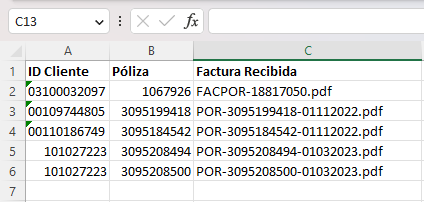
Como omitir las filas que se repite el dato más de una vez como en este caso que es “ID Cliente” y quedarme solo con una?
Como omitir las filas que se repite el dato más de una vez como en este caso que es “ID Cliente” y quedarme solo con una?
Hola @Jose_Miguel_Almonte,
Te voy a pedir algunos detalles más para entender mejor qué es lo que estás buscando lograr.
¿El objetivo es ignorar las filas enteras cuando el “ID Cliente” es repetido? Por ejemplo, en tu caso, querrías leer las 5 filas de la tabla (ignorando los encabezados) pero cuando llegas a la última, la ignorarías porque el “ID Cliente” es repetido - ¿es correcto esto? En ese caso, ¿qué querrías que pasara con los datos de las columnas “Póliza” y “Factura Recibida”, que son distintos?
Quedo al pendiente de tus comentarios para poder sugerirte una solución. ¡Gracias!
Si, es ignorar las filas enteras cuando el “ID Cliente” es repetido y solamente tomar una de ellas. Ya las columnas “Poliza” y “Factura Recibida” están dentro de una misma ruta (que se me olvido añadir la otra parte). La función de este bot es enviar dos o más facturas por correo electrónico y evitar la repetición de envios de un cliente y para eso me estoy guiando con el “ID Cliente” ya que es lo único que no puede cambiar dentro de la tabla.
Perfecto @Jose_Miguel_Almonte, ya me queda claro.
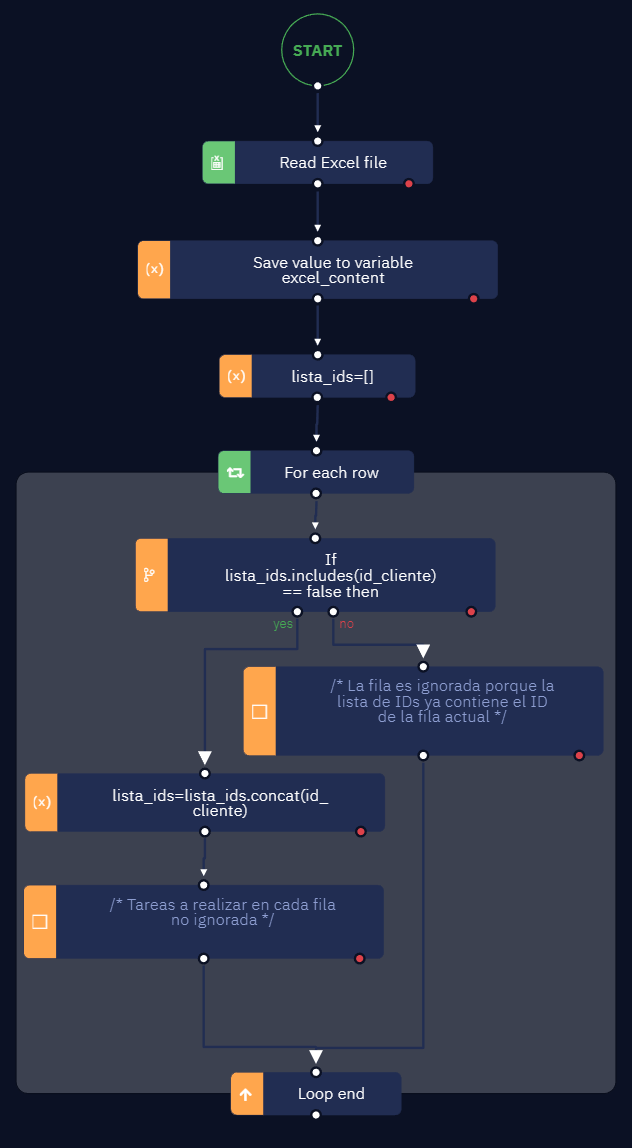
Lo que podrías hacer es crear una variable que contenga la lista de IDs ya procesados, y que al principio de tu loop iterando sobre cada fila, verifiques si el ID de la fila actual está incluído en esa lista. Si no lo está, primero se debe incluirlo, y luego se realizan las tareas que deseas realizar para cada fila. Si lo está, en cambio, la fila se ignora.
Así se vería el flujo:
La variable “lista_ids” se inicia simplemente como un Array vacío usando la opción “Calculate a value” e ingresando simplemente este valor:
[]
La condición que se verifica en la actividad If utiliza el método includes():
lista_ids.includes(id_cliente) == false
Y para agregar el “ID Cliente” actual a la “lista_ids”, usamos el método concat():
lista_ids.concat(id_cliente)
Esto te serviría para que las filas con IDs repetidos se ignoren. Más específicamente, se procesará la primera fila con dicho ID, luego cuando se detecte otra fila con el mismo ID, se ignorará.
Me avisas si esta propuesta se serviría (y puedes marcar mi respuesta como Solución), caso contrario me avisas y buscamos otra alternativa. ¡Muchas gracias!
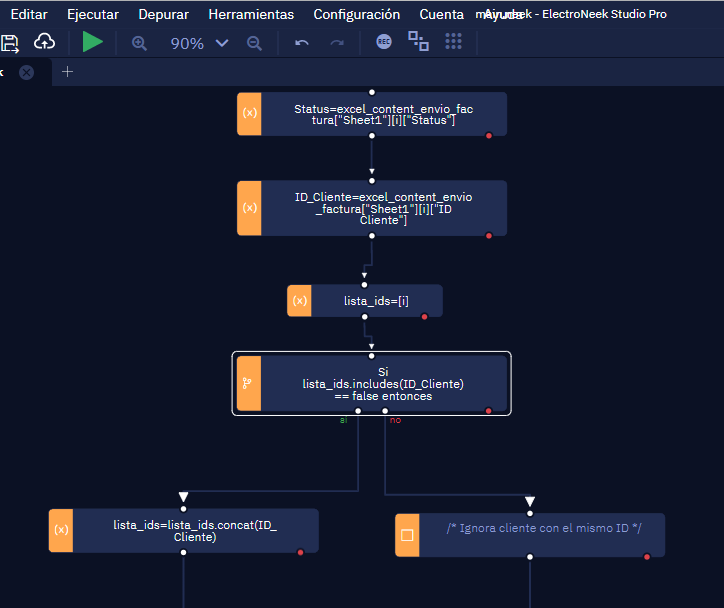
Y si lo hago de esta forma, que es usando el contador [i], puede funcionar. Porque quiero que también funcione de esa manera. ¿Será posible?
Qué tal @Jose_Miguel_Almonte,
Claro, en mi ejemplo utilicé la actividad “For each row”, pero tu método, usando un contador, es perfectamente válido también. La única diferencia es que debés asignar las variables (por ejemplo ID_Cliente) por separado, como en tu ejemplo ya bien haces, y además debes incrementar el contador y regresar a la condición “If” al final del bucle, para procesar la siguiente fila.
El único comentario es que no sería necesario inicializar “lista_ids” como “[i]”, puede continuar siendo un Array vacío. Después se le irán agregando los valores de “ID_Cliente”.
Quedo al pendiente por cualquier otra consulta al respecto. ¡Saludos!
Hola @Jose_Miguel_Almonte, Por favor, háganos saber si la solución que presentamos anteriormente funcionó para usted.
Siéntase libre de marcar la publicación en particular como una solución.